Trong nhiều đội kỹ thuật, nỗi đau không nằm ở chỗ không viết được code, mà nằm ở chỗ code chạy được nhưng không còn bám sát spec. Trước đây, khoảng cách này đã tồn tại. Nhưng trong thời AI, nó trở nên nguy hiểm hơn vì mã được tạo ra nhanh hơn nhiều so với tốc độ con người có thể hiểu, xác minh và kiểm soát.
Khi một nhóm dùng AI coding tools để tăng tốc delivery, điều họ thường nhận được đầu tiên là cảm giác năng suất tăng mạnh: feature ra nhanh hơn, pull request dày hơn, prototype có ngay trong vài phút. Nhưng đi kèm với tốc độ đó là một loại nợ mới: nợ kiểm soát. Hệ thống có thể lớn lên nhanh chóng trong khi mức độ truy vết giữa yêu cầu ban đầu, quyết định thiết kế và đoạn mã thực thi lại mờ dần.
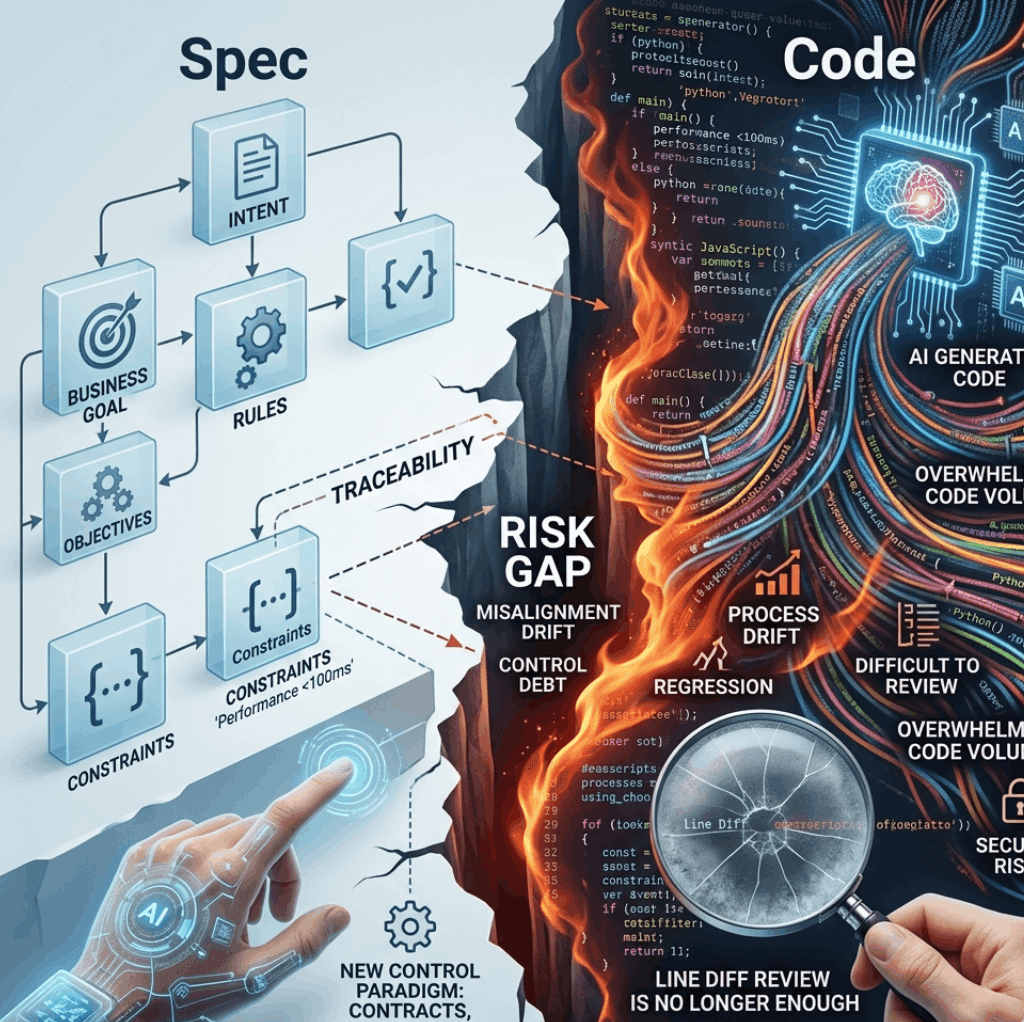
Spec và code khác nhau ở đâu?
Spec là mô tả về ý định: hệ thống cần làm gì, trong ranh giới nào, theo quy tắc nào, với ai, ở ngữ cảnh nào. Nó có thể bao gồm business rule, luồng nghiệp vụ, ràng buộc dữ liệu, điều kiện lỗi, phi chức năng, bảo mật, audit, SLA và cả những điều không được phép xảy ra.
Code là hiện thân kỹ thuật của một cách hiểu cụ thể về spec. Nó không chỉ là logic xử lý, mà còn là cấu trúc module, interface, dependency, migration, queue, retry, cache, log, monitoring và vô số giả định ngầm do người viết hoặc công cụ sinh mã đưa vào.
Vì vậy, spec và code không bao giờ là một. Giữa chúng luôn tồn tại một lớp chuyển dịch: từ ý định sang triển khai. Vấn đề bắt đầu khi lớp chuyển dịch này không được kiểm soát chặt chẽ.
Vì sao khoảng cách này nguy hiểm hơn trong thời AI?
AI không chỉ giúp viết nhanh hơn. Nó còn khiến số lượng thay đổi tăng lên, phạm vi thay đổi rộng hơn và mức độ tự tin bề ngoài cao hơn. Một đoạn code sinh ra trông rất hợp lý, thậm chí có test, có comment, có cấu trúc sạch. Nhưng điều quan trọng nhất vẫn chưa được đảm bảo: nó có đúng với ý định ban đầu không?
Đây là chỗ mà nhiều đội rơi vào bẫy của vibe coding: nhìn thấy output có vẻ đúng, chạy qua vài case có vẻ ổn, rồi cho rằng bài toán đã được giải. Trên thực tế, hệ thống có thể đang âm thầm lệch khỏi spec theo những cách khó thấy bằng mắt thường.
Trong mô hình làm phần mềm kiểu contract-first hoặc vận hành như một software factory, điều quan trọng không phải là tạo ra càng nhiều code càng tốt, mà là đảm bảo mọi thay đổi đều có thể lần ngược về đúng hợp đồng ban đầu: yêu cầu nào sinh ra thay đổi nào, test nào xác minh nó, rủi ro nào đã được khóa lại. Nếu thiếu traceability, AI chỉ làm cho tốc độ tạo sai lệch tăng lên.
Vì sao human review theo từng dòng không còn scale?
Trong nhiều năm, đội kỹ thuật dựa nhiều vào code review để giữ chất lượng. Cách này hiệu quả khi tốc độ thay đổi còn nằm trong vùng mà reviewer có thể thật sự đọc, hiểu và mô phỏng tác động của từng diff. Nhưng khi AI hỗ trợ sinh mã ở quy mô lớn, reviewer bắt đầu phải đối mặt với một thực tế khác.
- Pull request dài hơn và xuất hiện dày hơn.
- Code trông mạch lạc nên tạo cảm giác an toàn giả.
- Thay đổi nhỏ ở một điểm có thể kéo theo tác động xuyên nhiều lớp.
- Reviewer khó giữ được toàn bộ bối cảnh nghiệp vụ, kiến trúc và lịch sử quyết định trong đầu.
Khi đó, human review không scale nếu nó chỉ dừng ở việc soi từng dòng diff. Reviewer có thể phát hiện lỗi cú pháp, mùi code hay vi phạm convention, nhưng lại bỏ sót câu hỏi lớn hơn: thay đổi này có còn đúng với contract, có phá vỡ giả định của hệ thống, có tạo regression ở luồng khác hay không?
Bốn kiểu rủi ro phổ biến khi spec lệch code
1. Lệch ý định
Đây là dạng phổ biến nhất. Spec yêu cầu một hành vi cụ thể, nhưng code hiện thực một phiên bản “na ná” vì AI hoặc người viết suy luận thiếu ngữ cảnh. Ví dụ, yêu cầu nói rằng chỉ manager mới được duyệt đơn vượt hạn mức, nhưng code lại cho phép bất kỳ user có role nội bộ đều thực hiện được.
2. Lệch kiến trúc
Một thay đổi nhìn bề ngoài giải quyết xong bài toán, nhưng làm sai nguyên tắc phân tầng, vượt qua boundary của domain, hoặc tạo dependency không nên có. Hậu quả không lộ ngay trong sprint hiện tại, nhưng tích tụ thành hệ thống khó bảo trì, khó thay thế và khó kiểm soát về sau.
3. Lệch quy trình
Nhiều nghiệp vụ không chỉ là kết quả cuối cùng, mà còn là cách đi tới kết quả đó. Ví dụ cần ghi audit trước khi cập nhật trạng thái, cần qua bước approval trước khi xuất dữ liệu, hoặc cần phát event để đồng bộ hệ khác. AI có thể sinh ra code cho kết quả đúng ở màn hình trước mắt, nhưng bỏ qua một mắt xích quan trọng trong workflow.
4. Hồi quy
Regression không nhất thiết đến từ thay đổi lớn. Một chỉnh sửa rất nhỏ trong validation, mapping hoặc query condition có thể làm vỡ một use case cũ. Càng nhiều code được sinh nhanh, xác suất xuất hiện hồi quy càng cao nếu đội ngũ không có cơ chế kiểm soát theo hành vi và contract.
Nhìn vấn đề ở cấp workflow, không chỉ ở cấp line diff
Nếu chỉ nhìn vào diff, ta thường hỏi: đoạn này có đúng cú pháp không, có gọn không, có tối ưu không? Nhưng để kiểm soát rủi ro trong thời AI, cần nâng câu hỏi lên cấp cao hơn:
- Thay đổi này gắn với yêu cầu nào?
- Yêu cầu đó đã được phát biểu đủ rõ chưa?
- Contract đầu vào, đầu ra và điều kiện lỗi đã được khóa chưa?
- Những hệ nào bị ảnh hưởng dây chuyền?
- Test nào chứng minh thay đổi này không gây regression?
- Có thể truy vết từ spec sang code, test và release hay không?
Đây là lý do nhiều đội bắt đầu chuyển từ tư duy “review code” sang tư duy “kiểm soát workflow tạo thay đổi”. Mục tiêu không phải ngăn AI viết mã, mà là buộc mọi thay đổi đi qua một pipeline rõ ràng: spec đủ chặt, contract rõ, test sinh từ yêu cầu, kiểm tra ảnh hưởng, rồi mới đến review triển khai.
Một ví dụ về thay đổi trông nhỏ nhưng gây ảnh hưởng dây chuyền
Giả sử có một thay đổi rất nhỏ: để tăng trải nghiệm người dùng, hệ thống cho phép tự động chuyển trạng thái đơn hàng từ pending sang approved nếu tổng tiền dưới một ngưỡng nhất định. Nhìn ở cấp code, đây chỉ là thêm vài điều kiện if-else.
Nhưng ở cấp workflow, thay đổi đó có thể kéo theo:
- Luồng audit không còn ghi nhận bước phê duyệt như trước.
- Module thông báo gửi sai loại sự kiện.
- Báo cáo nội bộ hiểu nhầm rằng mọi đơn approved đều đã qua người duyệt.
- API cho đối tác nhận trạng thái mới sớm hơn dự kiến.
- Các rule chống gian lận mất đi một điểm chặn quan trọng.
- Test cũ vẫn pass vì chỉ kiểm tra kết quả cuối, không kiểm tra hành trình xử lý.
Nếu chỉ review vài dòng code, thay đổi này có vẻ sạch và hợp lý. Nhưng nếu soi từ spec và contract hệ thống, đây là một thay đổi có tác động lan rộng. Đó chính là bản chất của khoảng cách giữa spec và code: code có thể đúng cục bộ nhưng sai ở cấp hệ thống.
Từ AI coding sang kiểm soát đầu ra
Vấn đề của AI coding hiện nay không phải là nó viết code tệ trong mọi trường hợp. Vấn đề là nhiều đội đang tối ưu quá mạnh cho tốc độ sinh mã, trong khi năng lực kiểm soát đầu ra chưa được nâng cấp tương ứng. Khi đó, càng nhanh càng dễ đi lệch.
Hướng đi bền vững hơn là chuyển trọng tâm từ “làm sao sinh nhiều code hơn” sang “làm sao kiểm soát thay đổi tốt hơn”. Điều này thường bao gồm:
- Đặc tả yêu cầu rõ ràng hơn trước khi sinh mã.
- Thiết kế theo contract-first để khóa ranh giới hành vi.
- Duy trì traceability từ yêu cầu đến code, test và release.
- Tự động hóa kiểm tra hồi quy ở cấp hành vi, không chỉ unit test cục bộ.
- Review ở cấp workflow và kiến trúc, không chỉ ở cấp line diff.
- Dùng AI như công cụ tăng tốc triển khai, không phải nguồn chân lý cuối cùng.
Với các đội xây sản phẩm hoặc vận hành như một software factory, đây không còn là lựa chọn mang tính quy trình đẹp đẽ, mà là điều kiện để scale an toàn. Midi Coder hay bất kỳ nền tảng nào theo hướng contract coding đều chỉ có ý nghĩa khi giúp thu hẹp khoảng cách giữa ý định và triển khai, chứ không phải làm cho khoảng cách đó lớn hơn nhưng khó nhìn thấy hơn.
Kết lại, trong thời AI, câu hỏi quan trọng không phải là “code được viết nhanh đến đâu”, mà là “đội ngũ còn chứng minh được mức độ đúng của thay đổi đến đâu”. Khi tốc độ tăng mạnh mà khả năng truy vết và kiểm soát không theo kịp, khoảng cách giữa spec và code sẽ trở thành điểm rủi ro lớn nhất của kỹ thuật hiện đại.