Mở bài: nỗi đau thật của đội kỹ thuật
Khi AI coding tools giúp tạo mã nhanh hơn, cảm giác đầu tiên thường là năng suất tăng mạnh. Nhưng sau vài sprint, nhiều đội kỹ thuật bắt đầu gặp một vấn đề quen thuộc: regression xuất hiện ở những chỗ tưởng như không liên quan. Một thay đổi nhỏ, một refactor trông có vẻ hợp lý, hay một đoạn mã được sinh ra rất nhanh có thể làm hỏng luồng cũ, phá vỡ giả định kiến trúc hoặc tạo ra lỗi dây chuyền mà không ai nhìn thấy ngay lúc review.
Vấn đề không nằm ở việc AI có viết được code hay không. Vấn đề là khi tốc độ sinh mã tăng quá nhanh, đội ngũ rất dễ tích lũy nợ kiểm soát. Nếu vẫn dùng cách review truyền thống theo từng dòng, con người sẽ nhanh chóng trở thành nút thắt cổ chai. Và khi human review không scale, regression gần như là hệ quả tất yếu.
AI tạo tốc độ, nhưng cũng tạo nợ kiểm soát
Các công cụ sinh mã hiện nay rất giỏi ở việc tăng tốc khởi tạo: viết boilerplate, sinh test cơ bản, đề xuất refactor, nối API, dựng màn hình, thậm chí tự sửa lỗi theo vòng lặp. Trong môi trường áp lực delivery cao, điều này rất hấp dẫn. Tuy nhiên, tốc độ sinh mã không đồng nghĩa với tốc độ hiểu mã.
Mỗi lần AI đề xuất thay đổi, đội kỹ thuật phải trả lời nhiều câu hỏi hơn là chỉ “đoạn này có chạy không”:
- Thay đổi này có đúng với ý định nghiệp vụ ban đầu không?
- Nó có tôn trọng ranh giới giữa các module không?
- Nó có đi đúng workflow phát triển của đội không?
- Nó có làm suy yếu hành vi cũ mà test hiện tại chưa phủ hết không?
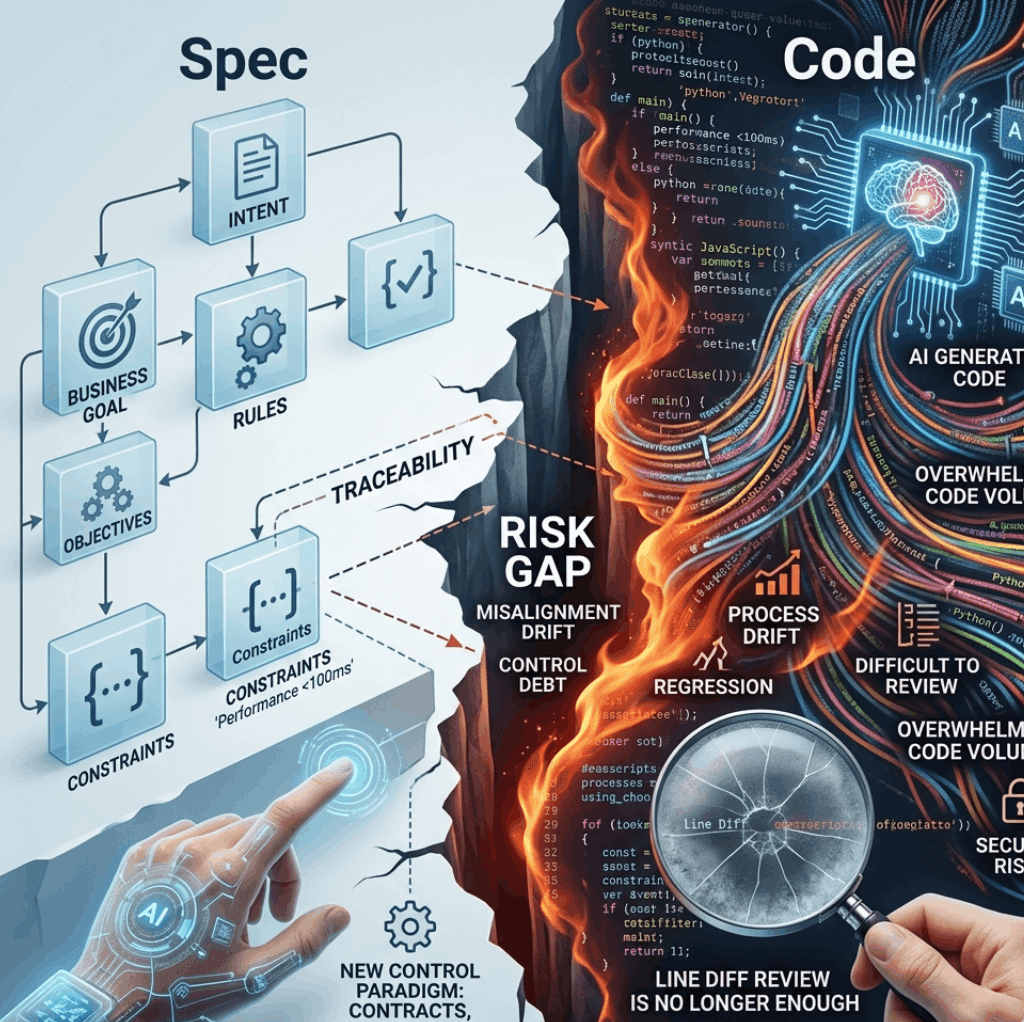
Nếu không có cơ chế traceability tốt, tức là không lần được từ yêu cầu đến quyết định, từ quyết định đến thay đổi, và từ thay đổi đến kết quả kiểm thử, thì code sinh nhanh sẽ biến thành rủi ro sinh nhanh.
Vì sao review theo từng dòng không còn đủ
Trong giai đoạn trước đây, reviewer có thể đọc diff, hiểu bối cảnh, đối chiếu logic và đánh giá mức độ an toàn của một thay đổi. Nhưng với vibe coding và các vòng lặp sinh mã liên tục, khối lượng diff có thể tăng nhanh hơn rất nhiều so với năng lực hấp thụ của con người. Reviewer bắt đầu chỉ còn kiểm tra bề mặt: cú pháp ổn, tên biến ổn, test chạy qua, vậy là merge.
Đây là điểm nguy hiểm. Regression do AI sinh mã hiếm khi lộ diện ở cấp độ một dòng code xấu. Nó thường nằm ở cấp độ quan hệ giữa nhiều phần của hệ thống: hợp đồng API bị lệch, giả định xử lý trạng thái bị thay đổi, thứ tự gọi dịch vụ bị đảo, hoặc một nhánh xử lý ngoại lệ bị vô tình rút gọn. Những lỗi này không dễ phát hiện nếu chỉ nhìn line diff.
Nói cách khác, review line-by-line vẫn cần, nhưng nó không còn đủ để kiểm soát đầu ra khi đầu vào là một dòng chảy thay đổi quá lớn và quá nhanh.
Regression thường bắt đầu từ 4 kiểu lệch phổ biến
1. Lệch ý định
AI có thể viết đoạn mã “hợp lý” theo prompt hiện tại nhưng không phản ánh đầy đủ ý định nghiệp vụ ban đầu. Ví dụ, yêu cầu là tối ưu tốc độ tải dữ liệu cho màn hình báo cáo, nhưng mã được sinh ra lại lược bỏ một bước xác thực từng rất quan trọng với đội vận hành. Về mặt kỹ thuật, code mới có thể sạch hơn và nhanh hơn. Về mặt sản phẩm, nó đã đi sai hướng.
2. Lệch kiến trúc
Nhiều regression bắt đầu khi AI vô tình nối tắt qua một lớp kiến trúc để “giải quyết nhanh”. Chẳng hạn, thay vì đi qua service chuẩn, mã mới truy cập thẳng repository hoặc gọi trực tiếp một endpoint nội bộ. Thay đổi này có thể giúp tính năng chạy được ngay, nhưng nó phá vỡ contract-first design, làm yếu ranh giới hệ thống và khiến các phần khác khó dự đoán hành vi hơn.
3. Lệch quy trình
Không ít lỗi phát sinh không phải vì code sai, mà vì code đúng theo một quy trình không tồn tại trong tổ chức. Ví dụ: AI thêm logic fallback, auto-retry hoặc silent handling lỗi mà không bám theo policy thật của đội. Khi đó, hệ thống trông có vẻ “mượt” hơn, nhưng lại làm mất tín hiệu quan trọng cho giám sát, debug và truy vết sự cố.
4. Hồi quy hành vi
Đây là dạng dễ thấy nhất nhưng thường được phát hiện muộn nhất. Một thay đổi nhỏ ở hàm dùng chung, một điều chỉnh rule validation, hay một sửa đổi mapping dữ liệu có thể kéo theo ảnh hưởng tới nhiều luồng khác. Vì AI thường tối ưu cục bộ theo bài toán trước mắt, nó không tự nhiên nhìn thấy toàn bộ bề mặt ảnh hưởng nếu hệ thống thiếu mô tả hợp đồng và thiếu kiểm soát workflow.
Cần nhìn vấn đề ở cấp workflow, không chỉ cấp diff
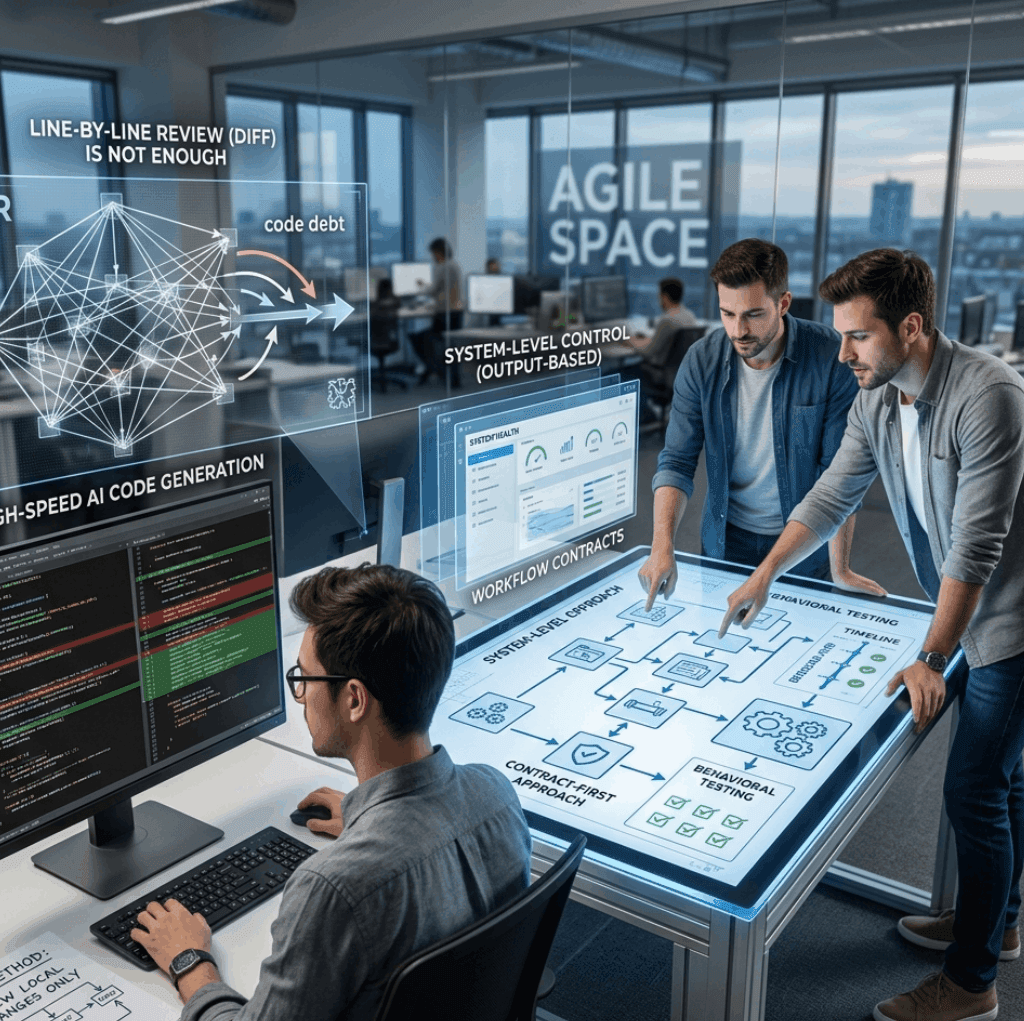
Nếu muốn giảm regression trong bối cảnh AI coding, đội kỹ thuật cần chuyển góc nhìn từ “AI viết code có đẹp không” sang “workflow tạo ra thay đổi này có kiểm soát được không”. Đây là chỗ mà các mô hình contract coding và contract-first trở nên quan trọng.
Thay vì để thay đổi bắt đầu từ code rồi mới cố review lại, workflow tốt nên bắt đầu từ hợp đồng rõ ràng: yêu cầu, phạm vi ảnh hưởng, tiêu chí chấp nhận, interface, điều kiện không được phá vỡ, và bằng chứng kiểm thử. Khi đó, mã chỉ là một đầu ra của quy trình, không phải trung tâm duy nhất của quy trình.
Trong cách tiếp cận kiểu software factory, điều quan trọng không chỉ là sinh mã nhanh mà là tạo được chuỗi kiểm soát có thể truy vết: ai yêu cầu, thay đổi nào được sinh ra, dựa trên contract nào, test nào xác nhận, và rủi ro nào đã được chấp nhận. Có traceability, đội ngũ mới có cơ hội kiểm soát tốc độ mà không đánh đổi độ tin cậy.
Một ví dụ về thay đổi nhỏ nhưng ảnh hưởng dây chuyền
Giả sử một AI coding tool được yêu cầu “dọn sạch” phần xử lý dữ liệu đầu vào để code gọn hơn. Nó phát hiện nhiều chỗ kiểm tra null lặp lại và quyết định gom chúng vào một helper dùng chung. Nhìn bề ngoài, đây là một refactor đẹp: ít dòng hơn, dễ đọc hơn, ít trùng lặp hơn.
Nhưng trong hệ thống thực tế, có thể mỗi luồng cũ lại có một sắc thái nghiệp vụ khác nhau:
- Một màn hình cho phép giá trị rỗng vì dữ liệu đến từ nguồn bên ngoài chưa chuẩn hóa.
- Một API nội bộ bắt buộc phải fail fast để hệ thống upstream biết mà xử lý lại.
- Một job nền chấp nhận thiếu trường tạm thời rồi bổ sung ở bước sau.
Khi helper mới áp dụng một cách thống nhất, các khác biệt ngầm này biến mất. Test hiện tại có thể vẫn pass nếu chưa phủ đủ ngữ cảnh. Reviewer có thể vẫn chấp nhận vì diff trông rất hợp lý. Nhưng sau khi deploy, từng luồng sẽ lỗi theo những cách khác nhau. Đây chính là kiểu regression rất điển hình của mã sinh nhanh: thay đổi nhỏ ở bề mặt, ảnh hưởng lớn ở hành vi.
Vì sao human review không scale trong kỷ nguyên vibe coding
Vibe coding đẩy nhanh chu kỳ thử - sửa - sinh lại. Điều đó có ích cho khám phá ý tưởng, nhưng nếu đưa thẳng vào quy trình delivery mà không bổ sung cơ chế kiểm soát, toàn bộ gánh nặng sẽ dồn lên reviewer và QA. Con người không thể liên tục đọc một lượng lớn mã sinh ra, giữ toàn bộ bối cảnh hệ thống trong đầu, rồi phán đoán chính xác mọi hệ quả kiến trúc và nghiệp vụ.
Khi review trở thành lớp phòng thủ cuối cùng, nó sẽ thất bại ở quy mô lớn. Không phải vì reviewer kém, mà vì bài toán đã đổi bản chất. Từ bài toán đọc code, nó trở thành bài toán kiểm soát sản xuất phần mềm ở cấp hệ thống.
Điểm mấu chốt: chuyển trọng tâm từ sinh mã sang kiểm soát đầu ra
Regression do AI sinh mã thường không bắt đầu từ một câu lệnh sai rõ ràng. Nó bắt đầu từ khoảng trống giữa tốc độ tạo ra thay đổi và khả năng kiểm soát thay đổi đó. Khoảng trống này xuất hiện khi ý định không được đóng gói thành contract, khi kiến trúc không được bảo vệ bởi ranh giới rõ ràng, khi quy trình thiếu traceability, và khi đội ngũ vẫn kỳ vọng human review có thể hấp thụ vô hạn.
Vì vậy, câu hỏi quan trọng không còn là “AI có thể viết bao nhiêu code mỗi ngày”. Câu hỏi đúng là “đội kỹ thuật đang kiểm soát đầu ra của AI bằng cơ chế nào”. Những nhóm làm tốt thường không chỉ dùng AI coding tools, mà còn đầu tư vào contract-first workflow, kiểm thử theo hành vi, traceability xuyên suốt và mô hình vận hành giống một software factory có kiểm soát.
Với những đội như Midi Coder theo đuổi contract coding, đây là khác biệt cốt lõi: không thần thánh hóa tốc độ sinh mã, mà đặt trọng tâm vào khả năng tạo ra thay đổi đúng ý định, đúng kiến trúc, đúng quy trình và có thể truy vết. Chỉ khi đó, AI mới thực sự giúp tăng năng suất mà không mở rộng bề mặt regression.